devstats 介绍
关于 devstats
devstats 是一个使用 HA Postgres 数据库和 Grafana 仪表盘来可视化 GitHub 存档的工具集。 所有的东西都是开源的,所以它可以被其他 CNCF 和非 CNCF 开源项目使用。唯一的要求是,项目必须托管在一个公共的 GitHub 仓库上。 CNCF 的 devstats 项目使用 Equinix 裸机 Kubernetes 节点部署,并使用 Helm 图部署。
在 TiDB 社区的应用
因为 devstats 支持其他项目使用,所以我们为 TiDB 社区部署了一套来帮助我们进行社区状况分析。(正在进行中)
关于本书
编写本书的目的:一方面是希望本书作为一本手册能够分析 devstats 的架构和记录它的部署流程,另外一方面也希望能够作为一个使用 devstats 的例子供其他社区参考。
数据来源
GH Archive
介绍
GH Archive 是一个记录 GitHub 公共时间轴的项目,将其归档,并使其易于访问,以便进一步分析。
记录形式
GH Archive 会将 GitHub 所有的事件通过 API 爬取并存储为 JSON 文件,然后将其整理上传到 Google Big Query 的公开数据集。
另外, GH Archive 在爬取过程中会对邮件信息进行混淆,防止数据集被利用暴露个人隐私。
devstats 会直接分析这些 JSON 文件作为数据来源。
GitHub API
介绍
GitHub 提供了两套 API 来让用户获取 GitHub 上几乎所有的数据:
记录形式
无论是 REST API 还是 GraphQL API 都可以以 JSON 的格式返回数据,devstats 会定时的去使用 API 获取数据作为数据来源。
Git
介绍
Git 作为一个分布式版本控制系统,存储了代码仓库所有的分支上的所有 commit。
记录形式
Git 存储了代码仓库的所有 commit,devstats 会克隆仓库,并从中获取文件级别的 commit 信息作为数据来源。
CNCF gitdm
介绍
CNCF gitdm 是 CNCF 对 gitdm 的一个 fork,用来计算开发者及其公司对开源项目的贡献。
记录形式
CNCF gitdm 将数据存储为 txt 和 JSON 文件,并且保持每个月一两次的更新。devstats 会将数据以 JSON 的格式导入到其中来作为数据来源。
数据收集方式
GH Archive
收集方式
devstats 会一次性将 GH Archive 所有的 JSON 文件逐个下载下来进行解析然后存储到 PostgreSQL 中,并且在该过程中会将数据分为固定数据和可变数据,将 event_id 作为可变数据的主键来进行维护和更新。
收集工具
devstats 使用 gha2db 工具来解析数据,并将数据存储到 PostgreSQL 中。
GitHub API
收集方式
devstats 主要利用 GitHub API 来补充和校正 GH Archive 中缺失或错误的数据。devstats 会通过定时任务来调用 GitHub API 获取两个小时以内的相关事件,并且把这些数据更新到 PostgreSQL 中。例如:Issue/PR 当前的 Label 或 Milestone 信息,就需要 API 尽快的来收集和更新。
收集工具
devstats 使用 ghapi2db 来调用 GitHub API 拉取数据并将数据存储到 PostgreSQL 中。
Git
收集方式
devstats 会将需要分析的仓库直接 clone 或者 pull 到本地,然后查看整个仓库的所有的 git log 并对它进行分析。devstats 会直接通过提交的 SHA 来定位改动并且统计改动大小信息。
收集工具
devstats 使用 get_repos 来 clone/pull 仓库,并对仓库的 git log 逐一分析。
CNCF gitdm
收集方式
CNCF gitdm 提供了一个存储开发者所属公司信息的 JSON 文件,该文件使用 Git LFS 方式存储。devstats 会从中解析出 GitHub 用户的公司信息,并与其他数据结合,这样我们就收集到了大部分贡献者的公司信息。
收集工具
devstats 使用 import_affs 来解析 JSON 文件将员工公开信息存储到数据库中。
数据存储方式
数据展示方式
架构
整体架构
架构图
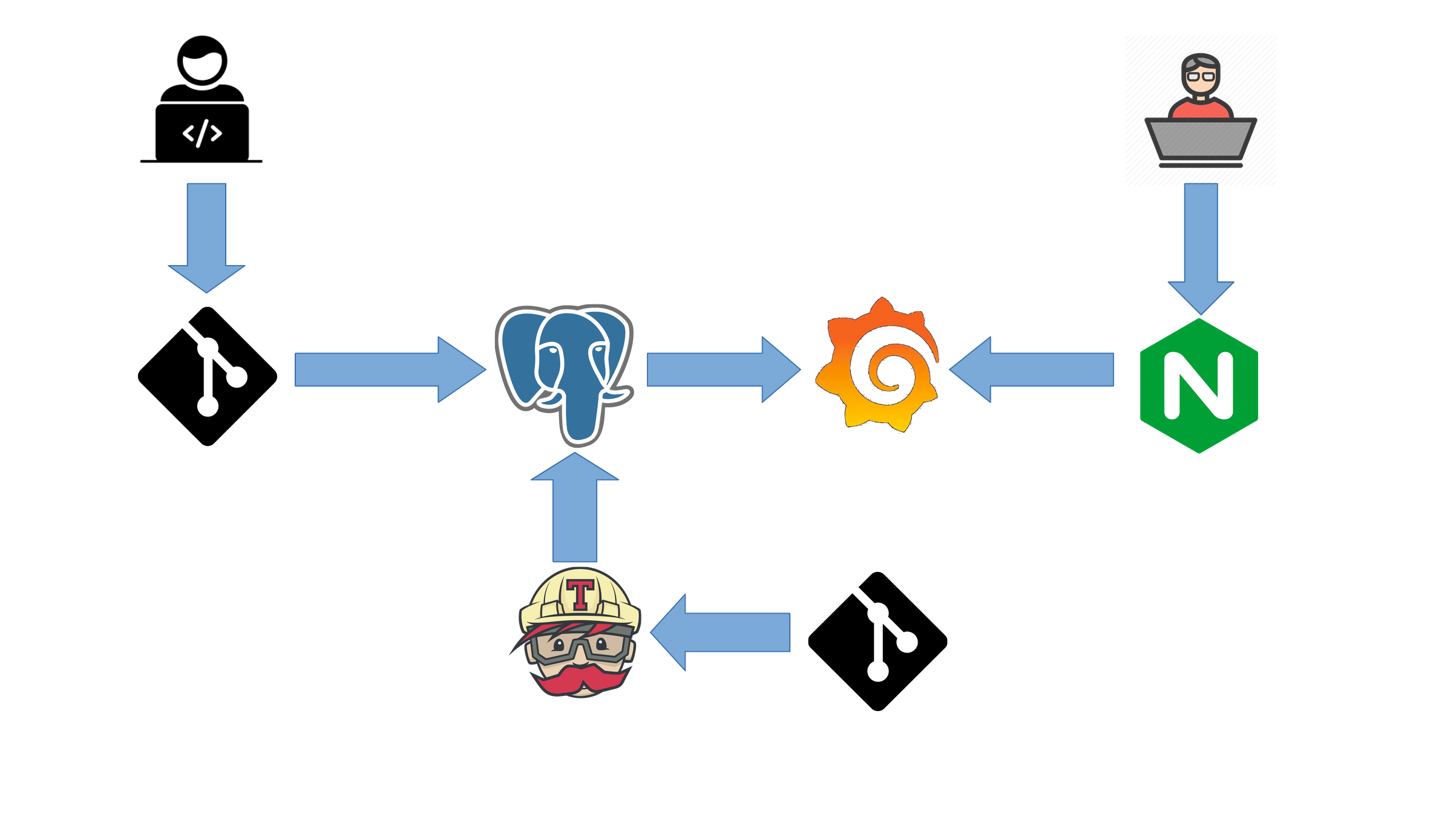
架构说明
当贡献者们在 GitHub 上活动时会产生相关的日志数据,我们会采用定时任务的方式每隔一小时将这些数据同步到 PostgreSQL 中,然后通过 Grafana 将数据展示出来给大家看。另外我们利用 Travis CI 对我们的改动进行测试和部署。
核心组件
- Grafana 用于展示数据
- PostgreSQL 用于存储数据
- 使用 Patroni 构建 PostgreSQL 集群保证高可用性
- Provisions 用于从各个数据源收集数据
- 在该组件中主要是使用 devstatscode 的代码来从各个数据源收集数据
数据库表
概述
单个数据库中包含了以下几类数据库表:
- 以
gha_为前缀的数据表存放的是从 GHArchive 中爬取过来经过结构化存储起来的基础数据 - 以
s为前缀的数据库表存放的是 series 数据,是 devstats 将基础数据经过指标计算出来的时序数据,这些数据会被 Grafana 通过查询得到,以图表或表格形式进行展示 - 以
t为前缀的数据库表存放的 tags 数据,是 devstats 从基础数据查询得到的一些列表数据,这些数据会在指标数据计算过程中、构建多列宽表表结构、Grafana 图表的下拉选项列表中使用到
视图
GhArchive 上的数据是用户在 GitHub 上产生的公开活动的事件数据,然而在一些查询场景下,我们往往只需要针对数据对象的最新状态进行查询,而不需要遍历过往的历史数据。为了简化这些查询工作,可以通过数据库的视图功能,根据历史数据来构建数据对象最新状态的模型。
Pull Requests
视图名:pull_requests
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
event_id | bigint | |
id | bigint | |
repo_name | varchar(160) | 注意:仓库可能存在更名行为 |
number | integer | 注意:Issue 与 Pull Request 的 Number 编号是统一的 |
title | text | |
state | varchar(20) | Pull Request 的状态,可以分为:open / closed |
body | text | |
assignee_id | bigint | |
milestone_id | bigint | |
milestone | varchar(200) | |
base_sha | varchar(40) | |
creator_id | bigint | 创建者的 Actor ID,可以通过连接 actors 视图获取创建者的更多信息 |
created_at | bigint | |
updated_at | timestamp | |
closed_at | timestamp | |
merged_at | timestamp | |
merge_commit_sha | varchar(40) | |
merger_id | bigint | 合并者的 Actor ID |
maintainer_can_modify | boolean | 是否允许 Maintainers (拥有仓库 Write 权限的用户) 进行修改 |
comments | integer | 评论的数量 |
review_comments | integer | Review 评论的数量 |
additions | integer | 添加代码总行数 |
deletions | integer | 删除代码总行数 |
changed_files | integer | 改变文件数量 |
Pull Request Assignees
Pull Request 当前分配的 Assignees。
视图名:pull_request_assignees
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
pull_request_id | bigint | |
assignee_id | bigint | 可与 actors 视图进行连接 |
Pull Request Requested Reviewers
Pull Request 当前请求过的 reviewers。
视图名:pull_request_requested_reviewers
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
pull_request_id | bigint | |
requested_reviewer_id | bigint | 可与 actors 视图基础数据表进行连接 |
Issues
视图名:issues
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
event_id | bigint | |
id | bigint | |
repo_id | bigint | |
repo_name | varchar(160) | 注意:仓库可能存在更名行为 |
number | integer | 注意:Issue 与 Pull Request 的 Number 编号是统一的 |
title | text | |
state | varchar(20) | Issue 的状态,可以分为:open / closed |
is_pull_request | boolean | |
body | text | |
assignee_id | bigint | |
milestone_id | bigint | |
milestone | varchar(200) | |
creator_id | bigint | |
created_at | timestamp | |
updated_at | timestamp | 最后的更新时间 |
closed_at | timestamp | |
comments | integer | 评论的数量 |
Issue Labels
视图名:issue_labels
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
issue_id | bigint | |
label_id | bigint | |
full_label | varchar(160) | 完整的标签名称,格式如:<prefix>/<label> |
prefix | varchar(160) | 标签的前缀,默认为 general,表示没有前缀 |
label | varchar(160) | 标签去掉前缀后剩下的部分 |
Milestones
视图名:milestones
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
event_id | bigint | |
id | bigint | |
repo_id | bigint | |
repo_name | varchar(160) | 注意:仓库可能存在更名行为 |
milestone | varchar(200) | |
state | varchar(20) | |
created_at | timestamp | |
updated_at | timestamp | |
closed_at | timestamp |
Comments
视图名:comments
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
event_id | bigint | |
id | bigint | |
repo_id | bigint | |
repo_name | varchar(160) | 注意:仓库可能存在更名行为 |
number | integer | 该值在 commit_comment 类型的评论中为空 |
commit_id | bigint | |
comment_type | varchar(20) | 可选类型:commit_comment / review_comment / issue_comment |
body | text | |
commit_id | bigint | 即 Commit SHA |
original_commit_id | bigint | 即 Commit SHA |
position | integer | |
original_position | integer | |
path | text | |
line | integer | |
diff_hunk | text | |
pull_request_review_id | bigint | |
creator_id | bigint | |
creator_login | varchar(120) | |
created_at | timestamp | |
updated_at | timestamp | |
issue_id | bigint | |
pull_request_id | bigint |
注意
commit_comment类型的评论可能出现在 Pull Request 的 Commit 当中,也可能出现在仓库分支上的 Commit,针对仓库分支上 Commit 的评论是不会包含issue_id、pull_request_id、number几个字段,直接通过 Commit SHA 与 Comment ID 来唯一确定一条评论,例如:chaos-mesh/chaos-mesh#41101958
已知问题
- 由于
gha_issues_pull_requests基础信息表的数据缺失,根据pull_request_id不一定能够找到对应的issue_id,建议使用number字段替代。
Commits
视图名:commits
注意:这里的 commit 不包含 Pull Request 当中的 commit,而包含
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
sha | bigint | |
event_id | bigint | |
message | text | |
is_distinct | boolean | |
author_id | bigint | |
author_name | varchar(160) | |
author_email | varchar(160) | |
committer_id | bigint | |
committer_name | varchar(160) | |
committer_email | varchar(160) | |
loc_added | integer | |
loc_removed | integer | |
files_changed | integer | |
repo_id | bigint | |
repo_name | varchar(160) |
Actors
视图名:actors
| 字段名 | 数据类型 | 附加说明 |
|---|---|---|
id | bigint | |
login | varchar(120) | |
name | varchar(120) | |
sex | varchar(1) | |
sex_prob | double | |
country_id | varchar(2) | 参照 gha_countries 基础数据表 |
country_name | text | |
tz | varchar(40) | |
tz_offset | integer | |
age | integer | |
company_name | varchar(160) | |
merged_prs | integer | |
is_code_contributor | boolean | 根据 PR 数量是否大于 1 来判断是否为代码贡献者 |
is_bot | boolean | 根据 gha_bot_logins 表的 pattern 判断该 login 的 actor 是否为机器人 |
部署流程
定制
自定义 Grafana 仪表盘
步骤
- 在已经运行的 Grafana 上添加新的 Dashboard 或对已有的 Dashboard 进行修改,并点击保存按钮进行保存;
- 通过
kubectl cp命令将 Grafana 实例所使用的 sqlite 文件 dump 下来;
kubectl cp devstats-grafana-pingcap-xxx:/root/grafana.pingcap.db ~/dump/grafana.pingcap.db
kubectl cp devstats-grafana-chaosmesh-xxx:/root/grafana.chaosmesh.db ~/dump/grafana.chaosmesh.db
kubectl cp devstats-grafana-tikv-xxx:/root/grafana.tikv.db ~/dump/grafana.tikv.db
- 切换到开发环境配置目录
cd configs/dev/
- 将 dump 下来的 sqlite 文件复制到
configs/dev/sqlite目录内; - 执行
dump_dashboard_json.sh脚本, 将 sqlite 目录下的 *.db 文件当中的 Dashboard 数据记录转换为 json 文件,存在在 sqlite 目录下。如果希望只对单个项目进行处理,可以通过在命令行前添加变量ONLY=<project_lowername>来指定;
ONLY=tikv dump_dashboard_json.sh
- 如果希望将新增或修改过后的单个 Dashboard 配置共享到其它项目当中,可以使用
add_dashboard.sh脚本进行复制;
FROM_PROJ=tikv add_dashboard.sh dashboard_name.json
- 如果希望将新增或修改过后的所有 Dashboard 配置共享到其它项目当中,可以使用
add_dashboards.sh脚本进行复制;
FROM_PROJ=tikv add_dashboards.sh
-
核对复制出来的 Dashboard 是否存在错误,因为复制脚本在复制之后后将配置当中的项目名修改为新的项目名,这个过程中可能会修改了不应该修改的项目名,例如:dashboards.json 配置当中包含了所有项目名的链接列表;
-
提交代码,并在开发环境服务器上进行测试。